ModelRiver Blog
Product updates, engineering insights, and AI industry perspectives from the ModelRiver team.



The Hidden Architecture Behind Reliable AI Agents
The technical decisions that separate AI agents that work in demos from AI agents that survive production — failover chains, prompt caching, request isolation, metered billing, and the infrastructure nobody talks about.

AI Agents Are Easy to Demo. Debugging Them in Production Is the Hard Part
AI agent demos always work. Production agents break in ways you can't even see. This post covers the five silent failure modes in multi-step agent systems and the debugging pattern that actually helps.


Top LLM Frameworks in 2026 (Compared + Use Cases)
A practical comparison of the best LLM frameworks in 2026 — LangChain, LlamaIndex, Haystack, Semantic Kernel, and more. Learn which one fits your use case, and why most LLM frameworks struggle in production.

Your AI Feature Works in Dev. Here's How to Make It Reliable in Production
A practical guide to adding auto-failover, exact-match caching, observability and response contracts to OpenAI-compatible AI apps without rewriting your integration.

Test AI workflows without burning tokens
How ModelRiver's Test Mode lets you build, test, and ship AI features without paying for every failed request, flaky response, or debugging loop.
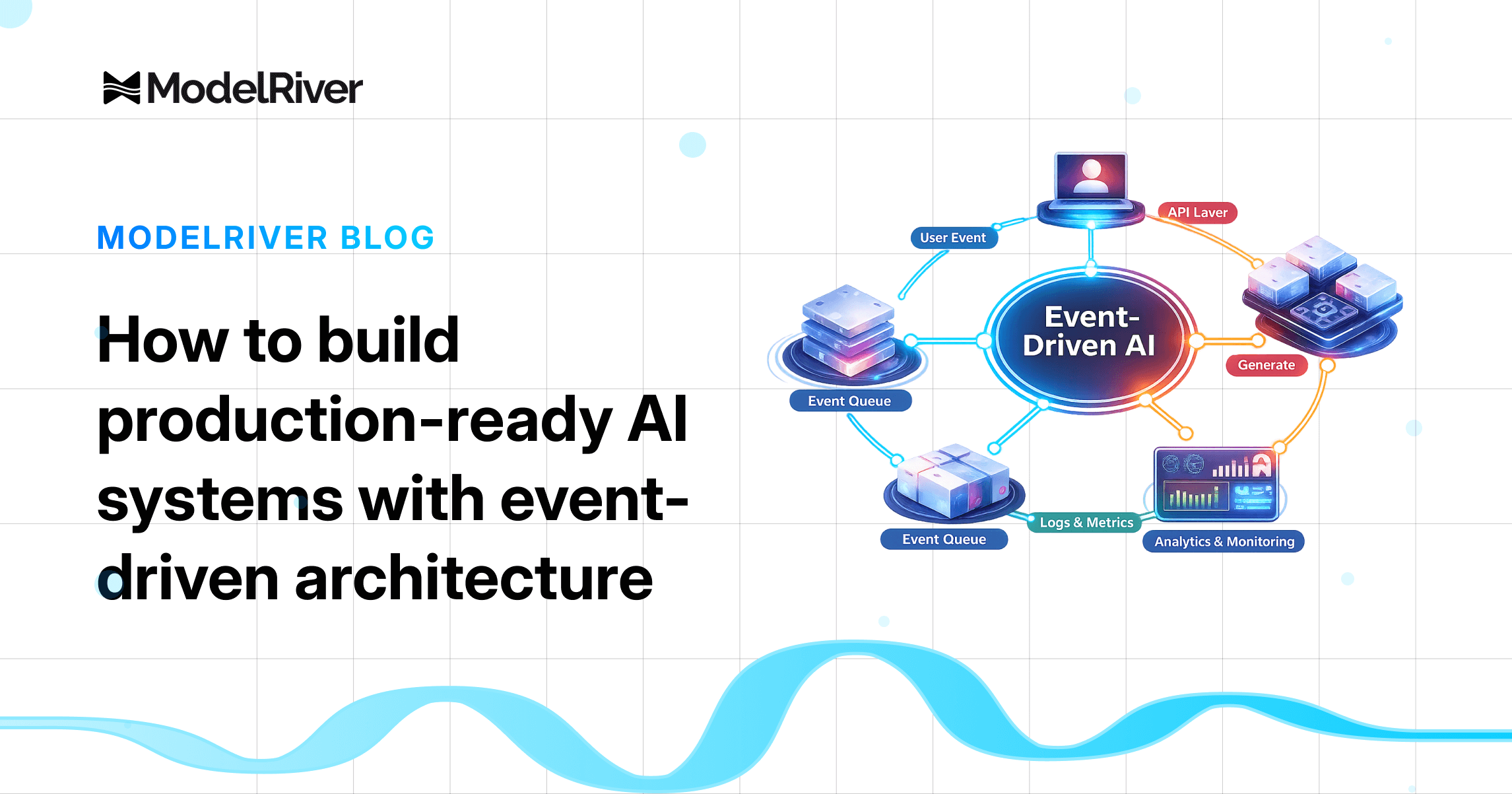
How to build production-ready AI systems with event-driven architecture
Learn how to build production-ready AI systems using event-driven architecture. Decouple AI generation from delivery, process webhooks, use callbacks, and stream results in real time.

Founders' note: Why we built ModelRiver
Discover why we built ModelRiver: real-time AI infrastructure, auto-failover, structured outputs, client SDKs, CLI, and observability for developers shipping AI products.